How I Reduce AI Coding Agent Hallucinations
When I hit a hallucination that annoys me, I've trained myself to pause and run through a short checklist.

Most engineers I pair with can spot an AI coding agent hallucination when it happens. The AI invents an API that doesn't exist, reaches for a deprecated library, or rewrites a function you explicitly said to leave alone. They notice it, they're annoyed by it, and they move on.
What I've noticed is that fewer engineers have developed the instinct to do something about it. Not just fix the output, but fix the input. When I hallucinate the same way twice, something in my environment is wrong, and I should go find it.
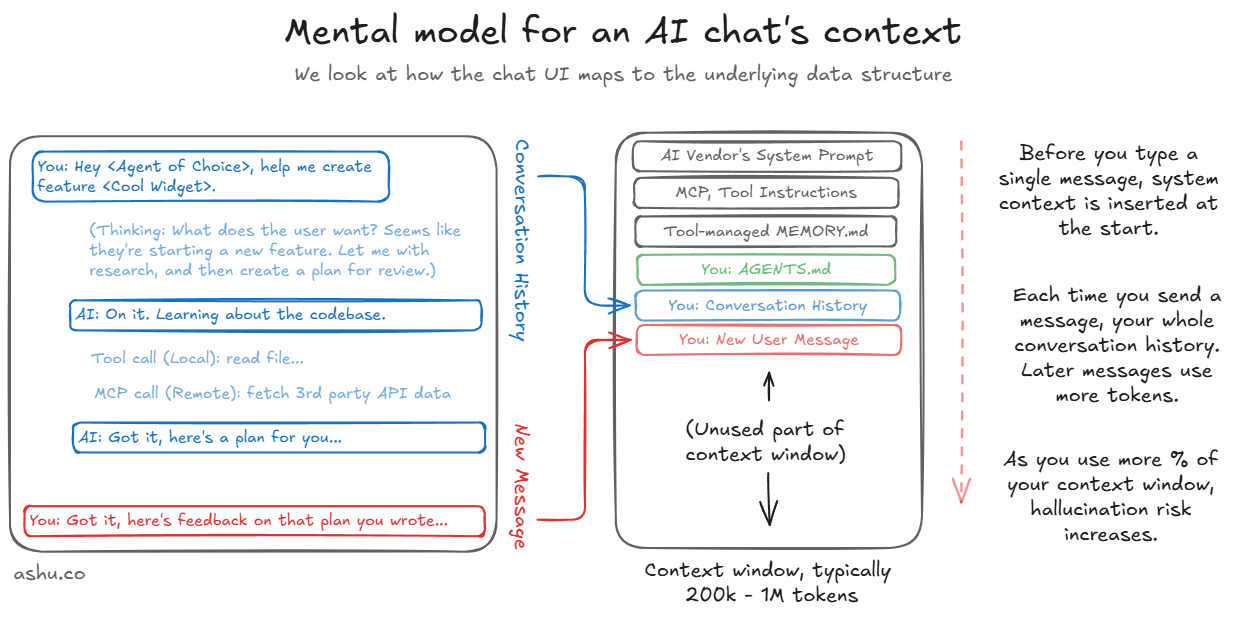
I won't rehash the anatomy of a conversation or why context limits matter. Dex Horthy described the "dumb zone" concept well in his talk on solving hard problems in complex codebases: the gist being that LLM performance degrades as the context window fills, roughly past the 40% mark. Most of those concepts still hold. What I want to share instead is a feedback cycle that I've been trying to teach to anyone who'll listen, along with the specific things I've learned applying it.
Most of us react to AI hallucinations. Few investigate.
I've seen a range of reactions when the agent goes off the rails: some people are amused, some get annoyed. In an extreme case, an engineer I know will ctrl+c out of the conversation the moment it goes sideways, which is fair. If the agent is heading in the wrong direction, stopping it saves tokens and time.
But the reaction I see less often is the one that actually improves the agent for the next run: pausing to figure out why it happened, and making a change so it doesn't happen again.
This matters beyond just your own workflow. Hallucinations are one of the biggest reasons skeptical engineers stay skeptical. Every time a teammate watches the AI confidently invent a nonexistent function, it reinforces the "these tools aren't ready" narrative. When you can help someone understand that there are actual knobs and levers to reduce hallucinations (not eliminate, but reduce) you're shoring up someone's confidence in the whole approach.
And to be clear: hallucinations will never go away entirely. There's a strong theoretical argument that they're a fundamental property of how these models work, rooted in the way these models compute. The goal isn't zero hallucinations. It's fewer, and faster recovery when they happen.
My tip is simple: reflect on what actually happened
When I hit a hallucination that annoys me, I've trained myself to pause and run through a short checklist. It's not sophisticated, but the habit of doing it consistently is what makes it work.
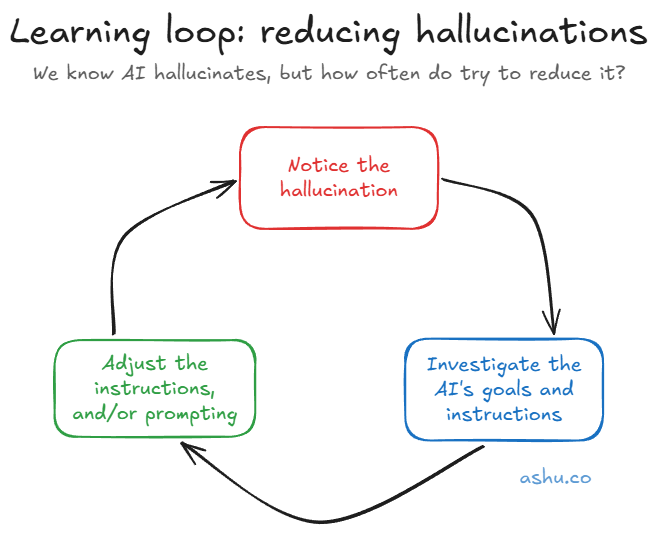
What did the AI coding agent actually hallucinate?
This sounds obvious, but I find that most people skip the diagnosis. They see the wrong output and immediately re-prompt or restart the conversation.
Instead, I look through the conversation history and try to trace the reasoning. What was the agent trying to do? What did I want it to do? Where did those two things diverge? Sometimes it's a genuine misunderstanding of my instructions. Sometimes the agent pulled in context from a file I forgot was in scope. Sometimes it's just the model being confidently wrong about a library API, which tells me something different about what needs fixing.
That last case is worth understanding. Researchers at OpenAI published a paper showing that LLMs are trained in a way that rewards guessing over admitting uncertainty, like a student who fills in an answer on every exam question rather than leaving any blank. Knowing this changes how I investigate. I'm not looking for a bug. I'm looking for missing context that would have steered the guess in the right direction.
Where did the context come from?
This is the core of it. When you've identified a hallucination worth fixing, the question becomes: what information did the agent use to make that bad decision?
First, you need to familiarize yourself with the sources of context your agent is consuming. In Claude Code, that's CLAUDE.md files, project-level memory in ~/.claude/projects/, any files it's read in the current session, and the conversation history itself. In Cursor, it's your rules files, your hierarchy of AGENTS.md files scattered throughout your repository, indexed docs, and whatever files are open or referenced. Each tool has its own anatomy, and it's worth spending an afternoon just mapping out where your agent gets its information.
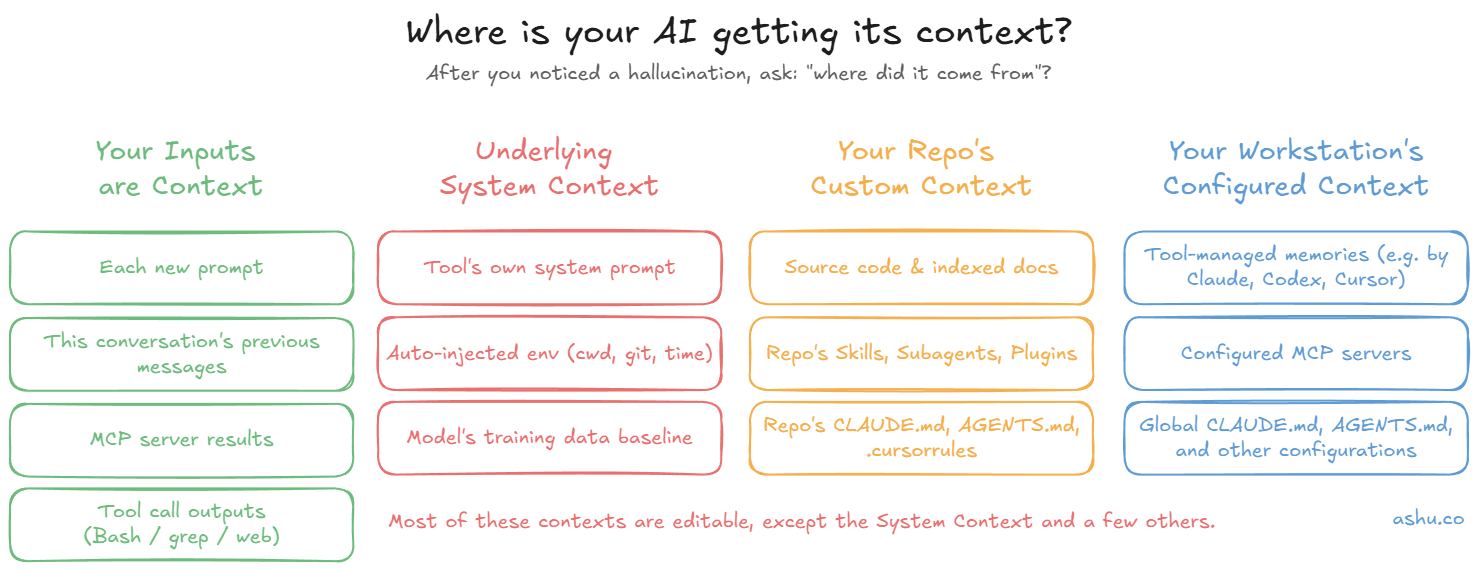
Once you know the anatomy, you can trace backwards from the hallucination. The agent thought it should use library X? Check if there's a stale reference in your rules file. It kept trying to write tests in a style you've moved away from? Maybe there's an old convention documented somewhere that you forgot to update. It invented an API endpoint? Maybe your schema docs are out of date, or maybe there are no schema docs and the agent is guessing.
When I can't figure it out on my own, I'll confront the agent directly. Something like: "I think you hallucinated here. I wanted you to do $X, but you did $Y. Why did this happen? What context did you use to make this decision, and what changes should I make to the rules files to avoid this in the future?"
Be direct, concrete, specific. The agent is often surprisingly good at self-diagnosing: it'll point to a rule it interpreted broadly, or a file it read that contained misleading information. Try out its suggested changes. They often work. Not always, but often enough that it's worth the 30 seconds to ask.
Is the "hallucination" a big enough issue to fix?
Before spending more time troubleshooting, I do a gut check. Maybe I disagreed with the approach, but is it actually wrong? Will the agent eventually get there?
Sidebar: when talking with a friend, he pointed out that "hallucination" isn't always the right term here. I'm actually referring to "all things you disagreed with an agent on". Hallucination is a distinct problem, but this advice applies to the broader set of problems. I use hallucination as a proxy term.
This is one of those things that's hard to learn from AI and easier to learn from serving as a manager. As a manager, you figure out that everyone does things differently. Sometimes an engineer takes a route you wouldn't have chosen, and the result is fine; it's often better than what you had in mind. I've started applying the same mentality to AI agents. If the approach is merely different from what I expected, I'll let it run for a while. The increased autonomy might be worth the extra time, even if the path isn't what I originally intended.
But if it's hallucinating facts, such as inventing APIs, fabricating function signatures, pulling in libraries that don't exist, that's a different category. That's when I stop and investigate.
Is your context too bloated? Smaller is better.
This one is counterintuitive, and I had to learn it the hard way. You'd think that giving the agent more instructions would make it smarter. More context about your database schemas, your API conventions, your testing preferences, your deployment pipeline... surely more information leads to better decisions?
In practice, there's a point where it flips. I went through a phase where I kept adding to my CLAUDE.md files every time something went wrong. Database schemas, model designs, interaction patterns, naming conventions. The file grew and grew (by month two it read less like documentation and more like a manifesto), and at some point the agent started getting worse. It was pulling in conflicting instructions, getting confused about which convention applied where, and occasionally just ignoring sections entirely.
Do you need this context every time? Or just some of the time? Can you extract this context, package it up as a Skill or Subagent and then trigger it when you need it?
This is where "context isolation" comes in. Instead of stuffing everything into the main rules file, you extract niche or complex use cases into separate mechanisms. The key insight is that subagents in particular have a stronger degree of context isolation, because the instructions don't load into the parent thread's context. You trigger them explicitly when you need them, and the rest of the time they're not competing for attention in the agent's working memory.
I ended up cutting my main CLAUDE.md from around 500 lines down to about 280 (it should probably be shorter), and moved the specialized stuff into skills that get invoked when relevant. The improvement was noticeable within a session or two.
Is the automatic memory working against you?
Most coding and chat tools manage a memory thread for you now. Claude Code keeps memories in ~/.claude/projects/$yourProject/memory/. Cursor has its own system. ChatGPT has its memory panel. The idea is good: the agent learns from your interactions and adapts over time.
The problem is that the agent doesn't always learn the right things. Andrej Karpathy flagged this a while ago on X: the model can obsess over a minor detail from 2 months ago that's completely irrelevant to what you're doing now. I've seen it happen in my own work: the agent latched onto a specific testing pattern I used once for a particular edge case, and kept invoking it on unrelated projects, long after it stopped applying.
In Claude Code, you can hunt for distracting memories in the memory directory and remove them, or ask Claude itself to clean up. In Claude's chat interface, you'll have to use the UI to inspect what it's stored and tell it what to change. (It doesn't let you edit memories directly, which is a minor annoyance.)
The broader point is that automatic memory is another source of context, and it can drift just like any other source. If your agent starts doing something odd that you can't trace to your rules files or the current conversation, check the memory. It might be holding onto something you'd rather it forgot.
Continuous learning with your AI, but you have to trigger it
Adding this trigger into my vibe coding repertoire has helped me improve the accuracy of my agents repeatedly. Even though AI work often feels a bit random, I keep a running list of problems. When something repeats itself, that's my signal that I might want to reflect and try to fix it. I'll pause and ask the agent to suggest changes to its own context that would prevent the issue in future runs. Then I test it on a controlled task to see if it sticks.
It's not a complicated habit, but it's a valuable one. Hallucinations cost you time, and that cost multiplies if you work on a team. If your teammates haven't run into a particular issue yet, you can save them time. And maybe they haven't developed this mental trigger yet. Sharing what you've fixed in your context files is one of the force-multiplying things you can do for a team adopting AI coding tools.
Most engineers I talk to treat their agent context like a set-and-forget thing. Write the AGENTS.md once, maybe tweak it when something goes really wrong. But context is a living system. It drifts, it bloats, it accumulates stale assumptions. The engineers who get the most out of these tools are the ones who treat context like code: something that needs regular review, refactoring, and testing.
This tweaking of the AGENTS.md files and other context is what I was referring to when I suggested looking at "concrete metrics of adoption" in my article measuring AI adoption as a manager.
If you've developed your own system for managing agent context, or if you've found patterns in how you debug hallucinations, I'd like to hear about it. DM me on LinkedIn.