Is Claude Code 5x Cheaper Than Cursor?
I ran 12 side-by-side experiments. At the same $200/month, Claude Code delivered roughly 5x more agent-hours. Here's the data, methods, and nuances.

In Part 1 of this series, I noticed something strange while using Claude Code's Max 20x plan: it was the same $200/month as Cursor Ultra, doing the same work, but my Claude Code utilization was stuck at 16% while I had been burning through Cursor's token budget. In Part 2, I figured out how to push past 50% utilization with parallel Claude Code agents.
Given that I could use so many more Sonnet/Opus tokens on Claude Code, my first instinct was: "is Claude Code actually 5x cheaper than Cursor?"
And then I realized you can't compare them apples to apples. I couldn't ask: at the same price, how much token capacity does each tool actually give you?. Their pricing models are enforced incredibly differently (see Part 1), Cursor has 2 pools of tokens (API, and "Auto + Composer").
So instead, I came up with a metric "agent-hours" to serve as a proxy: given each plan's token capacity, how many hours of agents can I run per month?
I had some hunches, but I couldn't be sure they would hold up. So, I did what any engineer with too much curiosity would do: I designed an experiment to find out.
A few key caveats to call out before we dive into it:
- This is a loosely controlled experiment, and not a rigorous benchmark.
- The findings are directional: order of magnitude, not precise. The readings fluctuated significantly day by day, and the product/capacity changed. But this reflects real life.
- I'm using Individual, not Team plans, focusing on $200 / month tiers.
- Things change rapidly in the world of vibe coding token use, models and costs
- The "1M context window" for Opus 4.6 dropped for Claude Code and then Cursor.
- Cursor dropped Composer 2.0, an upgrade from Composer 1.5
- Claude session limits were updated in between experiments
- I normalized for differing "2x limits" promotions in Claude Code and Codex.
- To see details about the experiment and its nuances, see below.
To return to the article: my intuition suggested there was a notable difference in price, and I wanted to quantify. I learned a considerable amount digging into pricing, and this helps me understand how to make the most out of the different models.
I hope this token and tool pricing analysis helps (and interests) you as much as it did me. It's a long article, but given the volatility of the experiment, I figured it would help for me to show you all the messy details and how I think about it.
The headline: Claude Code delivers ~5x more capacity per dollar
Here's the summary. At $200/month on individual plans:
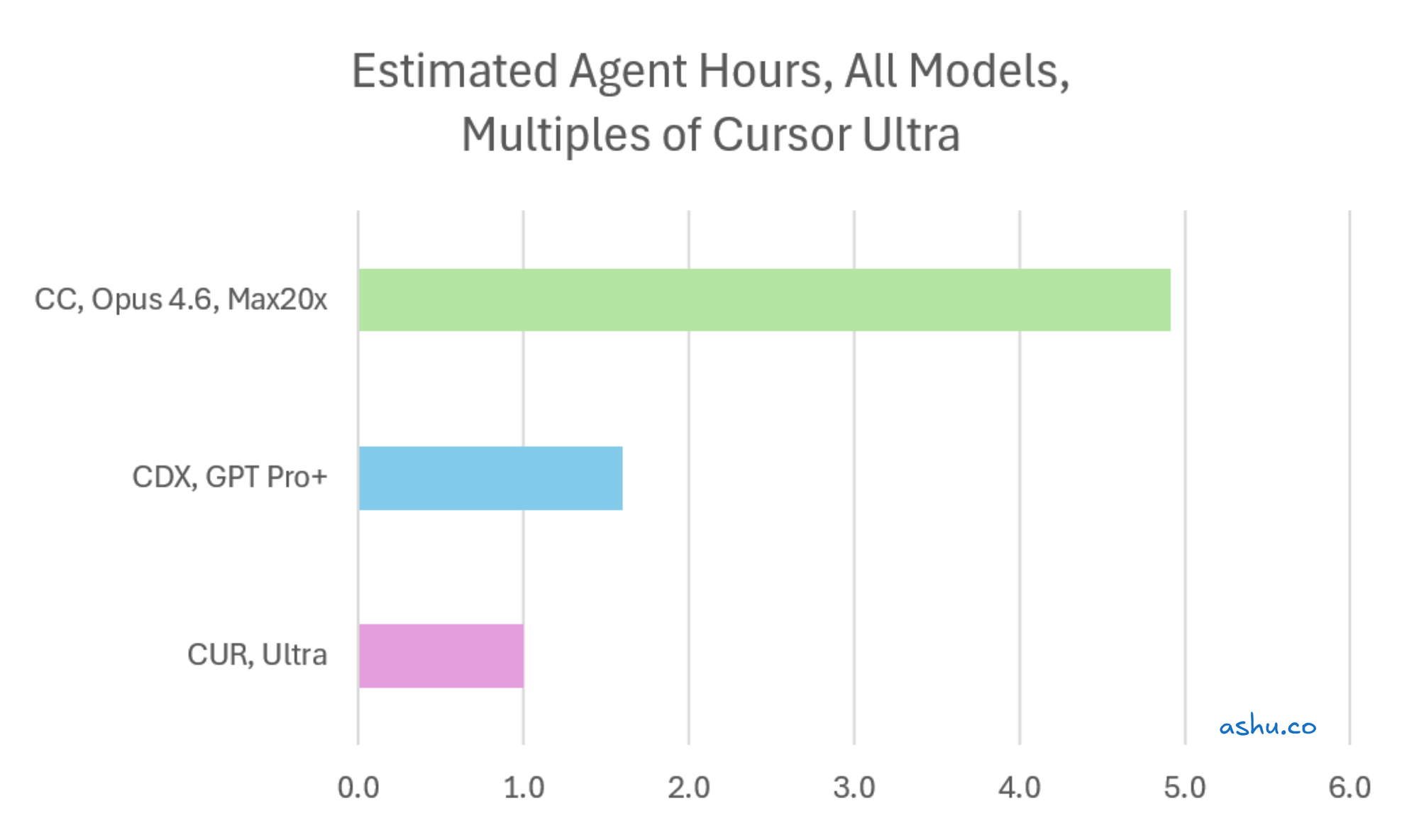
| Tool + Plan | Agent-Hours / Month | vs. Cursor Ultra |
|---|---|---|
| Cursor Ultra ($200) | ~138 hours | 1x |
| Codex Pro ($200) | ~220 hours | ~1.6x |
| Claude Code Max 20x ($200) | ~678 hours | ~4.9x |
So at the same $200/month, Claude Code gives you ~5x more room to work than Cursor.
Important context before we get further. This measures capacity per month (for my workload + codebase): how many agent-hours your subscription delivers if you use it fully. It does not measure work quality, code correctness, or features completed. You shouldn't read it as "5x cheaper" because that assumes you can actually use all that capacity.
But this is too simplistic of a view, because there are greater nuances to the pricing. We should next look at how Cursor's pricing works, because this makes the story considerably more interesting.
Cursor Ultra's pricing structure: two pools of different tokens
Before we go deeper into the comparison, we need to understand Cursor's pricing structure better. Cursor Ultra doesn't give you one big pool of tokens. It gives you two, and they're dramatically different in size and model characteristics.
- The first pool is API credits, which cover SOTA models: "state of the art" frontier models like Opus 4.6, Sonnet 4.6, and GPT-5.4 (at the time of publishing). These are usually the models scoring the highest on benchmarks, and also the most expensive models available.
- The second pool is "Auto+Composer" credits, which cover Cursor's proprietary Composer models — faster, cheaper models that Cursor has built and optimized for code generation.
When you upgrade to Ultra expecting unlimited access to the best models available, what you actually get is a small allocation of frontier model credits and a much larger allocation of Composer credits. Here's how the two pools break down:
| Cursor Ultra Usage Pool | Estimated Agent-Hours | % of total |
|---|---|---|
| API credits (We use Opus 4.6, both 200k and 1M) | ~18 hours | 13% |
| Auto + Composer credits | ~120 hours | 87% |
| Total | ~138 hours | 100% |
Note: API agent-hours depend on the price of the model you choose. Opus 4.6 is one of the most expensive options; a cheaper SOTA model would stretch further.
That ~18 agent-hours of frontier model is a key factor to consider when you use Cursor. When I ran experiments using only Opus 4.6 on Cursor, the API pool burned through fast. When I ran experiments using Composer models, the Composer pool lasted roughly 7–8x longer.
And this is a key finding: The combined 5x headline reflects what happens when you use Composer for most of your work, which is how Cursor intends for you to use it. Cursor incentivizes you to spend most of your time using the faster Composer 2 model. This seems to be a deliberate design choice, and it's a reasonable one. If you default to frontier models, the gap is far wider.
This explains a frustration I've seen across forums and from other engineers: you upgrade to Cursor Ultra and exclusively use SOTA models, only to find out that they hit their API credits faster than they'd expect.
Let's see what this looks like in numbers. We bring back the table above comparing tools, but we strip out the generous "Auto + Composer" tier, and exclusively use SOTA models. (Again, not the optimal use of Cursor.)
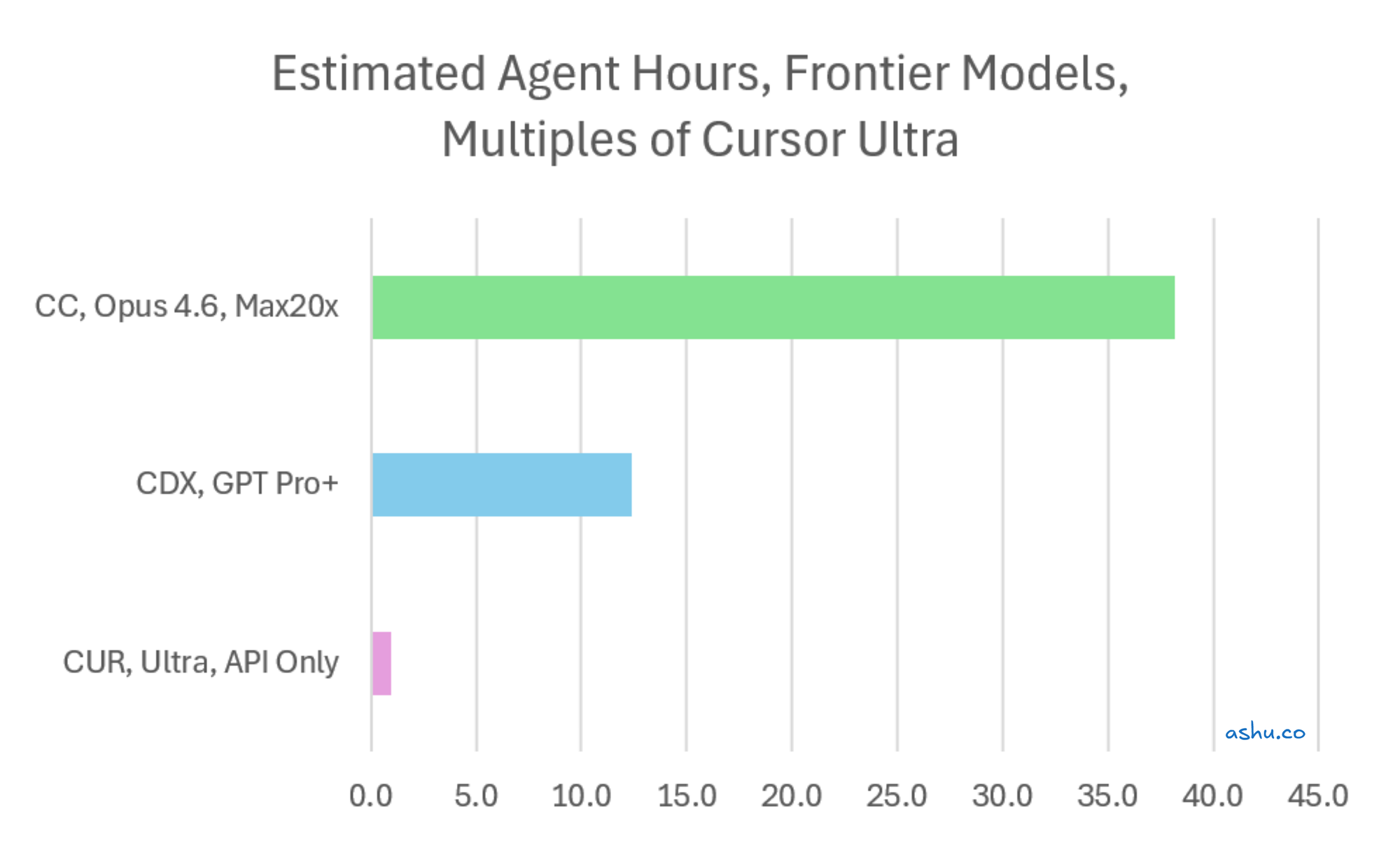
| Tool + Plan | Agent-Hours / Month (SOTA only) | vs. Cursor (SOTA) |
|---|---|---|
| Cursor Ultra — API only ($200) | ~18 hours | 1x |
| Codex Pro ($200) | ~220 hours | ~12x |
| Claude Code Max 20x ($200) | ~678 hours | ~38x |
That's a 38x difference in agent-hours (ignoring the vast amount of Composer 2 tokens that Cursor provides). For engineers exclusively focused on frontier model access for complex reasoning (Opus, GPT, Gemini) and you're comparing Claude Code to Cursor, this is the source of their surprise.
Even this is too simplistic; I think we need to dive deeper.
But capacity isn't velocity: Composer 2 is genuinely fast
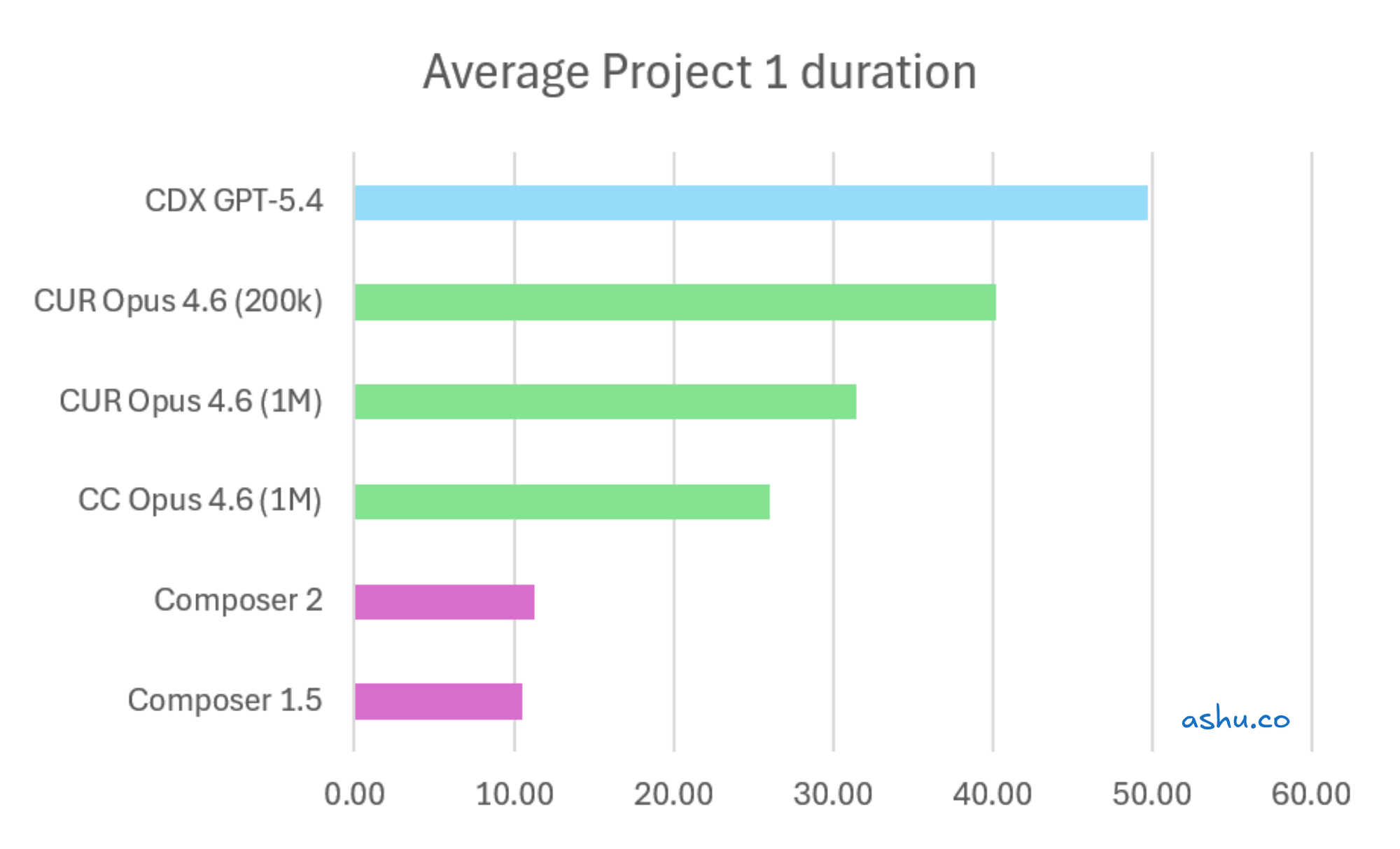
Here's where the story gets more interesting than "Tool A gives you more." I tracked project completions across all 12 experiments, and the velocity data tells a different story than the capacity data.
Here's how long the models took to complete Project 1, which involved a bulk rename across the project:
Next, let's look at Project 2, which involved cutting out a set of features out of the project:
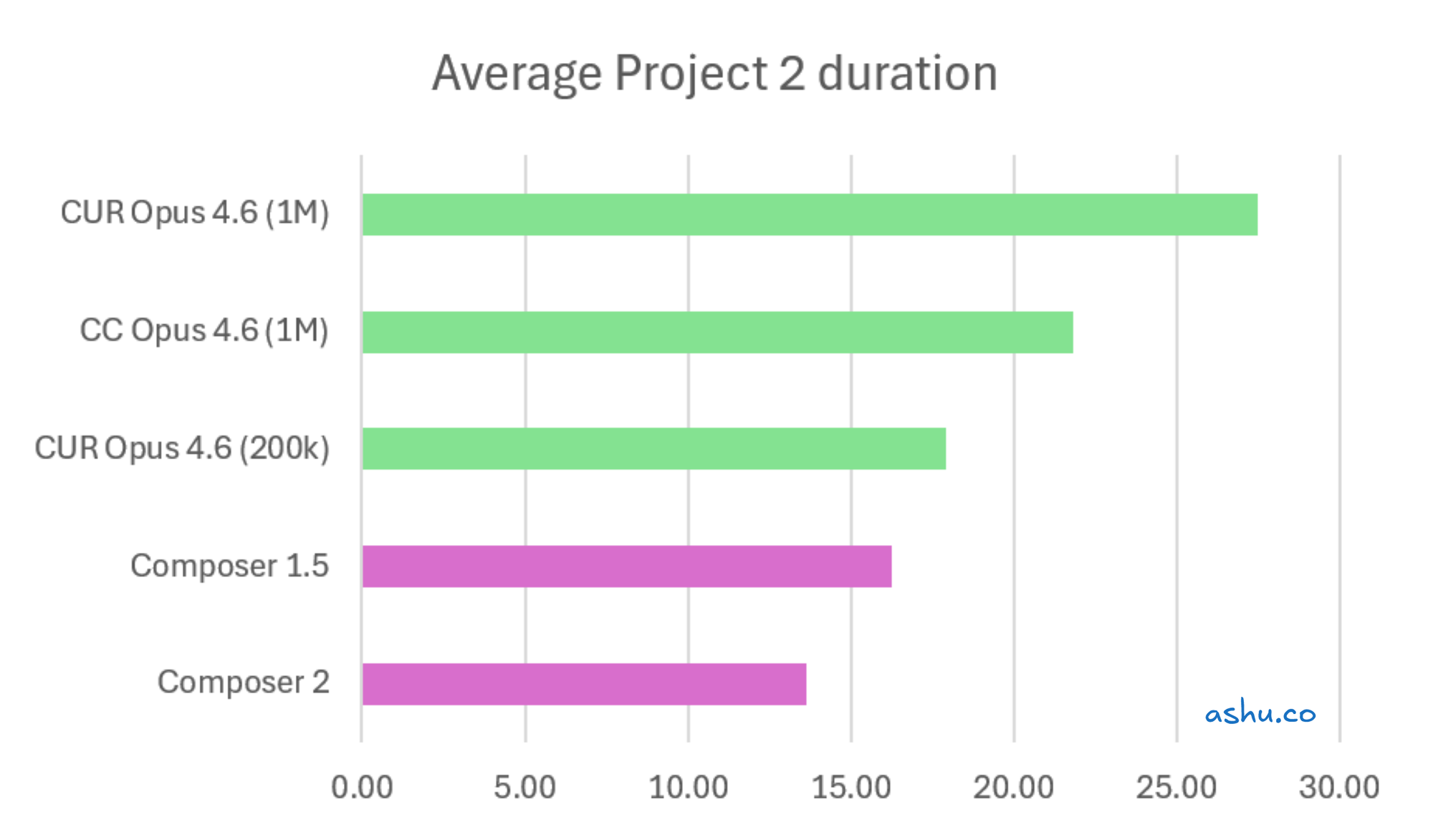
I think the first 2 charts provide a much better signal, because they compare 2 larger more complex refactor projects. They focus on the same project scope, and compare the models on that workload.
Caveat: I'm going to share the following chart, even though it's flawed. After the first 2 large projects, I queued up many small projects like "research X and then build a small full stack feature".
But nonetheless, I wanted to share the different feeling of speed as I worked with different models:
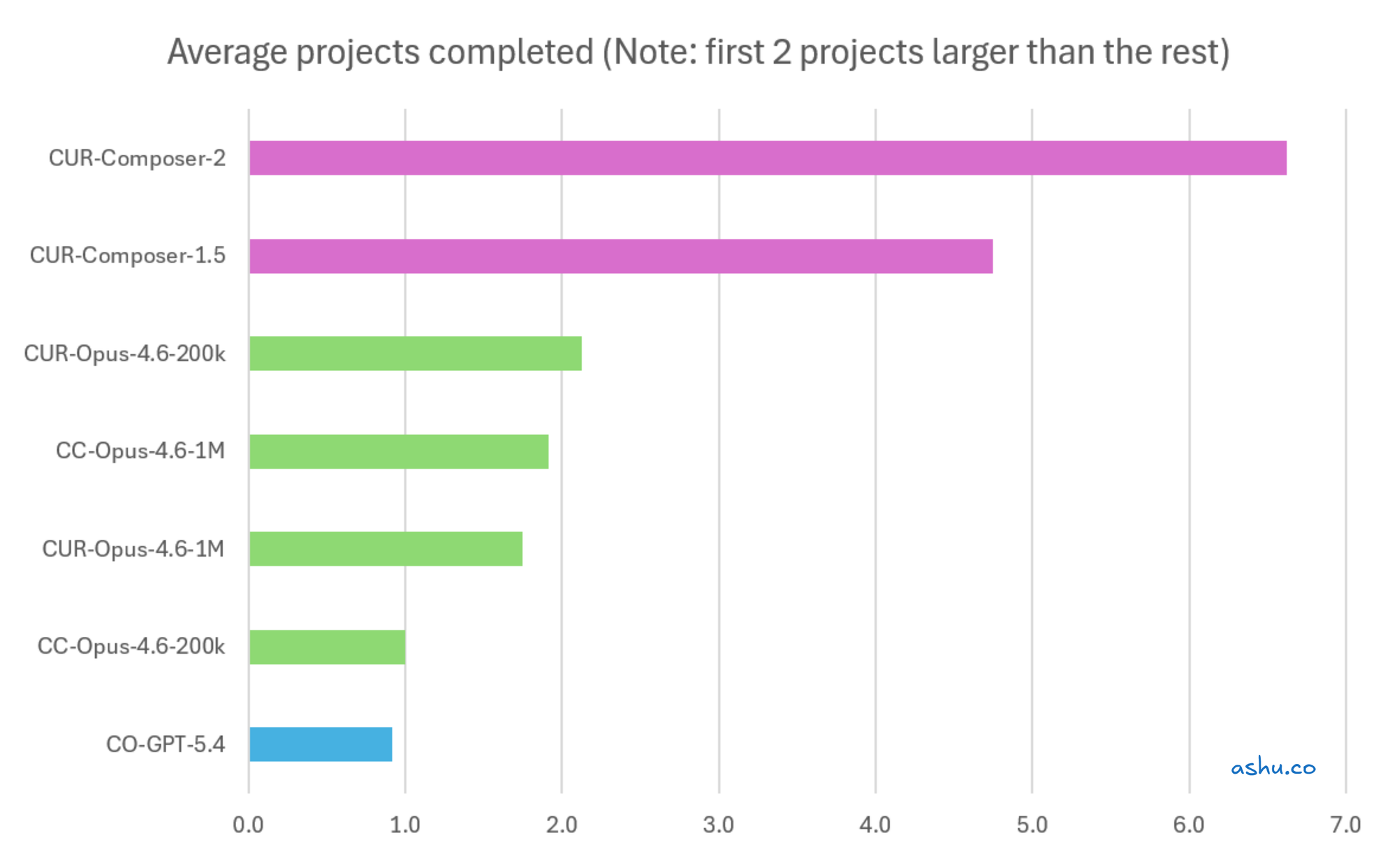
In all charts, the Composer models were at least 2x faster than the other models. Since it finished the first 2 larger projects, it was able to race ahead to do all the small projects at the end. On the other hand, this made the other models seem like they did less. But if you have a mix of small/large projects, Composer's lead may pull it ahead.
You might notice the Opus 4.6 200k / 1M models not showing a clear trend. The sample size was small, so the fluctuation is a bit noisy.
So, speed is another tradeoff when choosing tools. Claude Code may give you more capacity per dollar. But using Cursor Composer can dramatically increase throughput. If the work is clearly defined and implementation-focused, you may get more done in fewer agent-hours.
Now that I've walked through my findings on capacity and velocity, I'll walk through the actual experiment design.
A quick aside about Codex + GPT 5.4 performance and costs
If you're looking at Codex + GPT 5.4's velocity, you might notice that it didn't move as quickly. I wouldn't read too much into it. Each metric gives you a part of the picture; each tool has different strengths and weaknesses.
Firstly, I'm not as proficient at Codex's quirks as I am with Claude Code, so I don't know how to squeeze the most juice out of it. I noticed that during the experimental runs, GPT was much more cautious and spent more time slicing up the work into different groups.
And qualitatively, consider the multiple pieces of anecdotal evidence that Codex and GPT 5.4 can solve complex issues and that people are loving it. I've been hearing similar things in my conversations with colleagues. It's a potent tool and you should definitely give it a shot.
What I tested and how
The setup
I ran all 12 experiments on the same codebase: a monorepo with Elixir/Phoenix, React, and Terraform infrastructure, roughly 80k lines of code. Every experiment started from the same git commit. I used 4 parallel agents per tool, each on a separate git worktree (the same setup I described in Part 2). Each agent worked through the same sequence of self-contained refactoring projects: rename all instances of X, extract a module, add an API integration.
Each experiment ran roughly 60 minutes. I played a lightweight manager role — confirming "done" claims, assigning the next project. My controls tightened over the week as I learned what to watch for.
If you're interested in the raw data, reach out via LinkedIn or on X. If there's enough interest, I'd be happy to publish it on my Github. In the meanwhile, it's not a priority to properly format it for easy readability.
The tool configurations
| Detail | Claude Code | Cursor | Codex |
|---|---|---|---|
| Interface | CLI | CLI / Agent mode | CLI |
| Model | Opus 4.6 (200k, 1M context) | Opus 4.6 / Composer 1.5 / Composer 2 (varied) | GPT-5.4 |
| Plan tested | Max 5x ($100) | Pro+ ($60) → Ultra ($200) | Pro ($200) |
| Autonomy mode | Accept edits on | CLI with allow-listing (not YOLO) | Runs commands without asking |
| Parallel instances | 4 | 4 | 4 |
A few notes. I tested Claude Code on Max 5x ($100), not Max 20x ($200). The 20x projection uses Anthropic's published 4x multiplier: more on this in the calculations section. All three tools ran in semi-autonomous mode with different allow-listing behavior, which affects velocity asymmetrically and is unavoidable. Both Claude Code and Codex had active 2x capacity promotions during this period. Codex's promo applied 24/7. Claude Code's applied during specific off-peak hours.
What I measured
For Claude Code, I tracked the percentage of the 5-hour session consumed and the percentage of the weekly limit consumed. For Cursor, I tracked dollar amounts of API usage and Auto/Composer usage consumed, plus the combined total percentage. For Codex, I tracked the same session and weekly percentages as Claude Code.
How I calculated capacity
Defining "agent-hours"
An agent-hour equals one agent running for one hour. If 4 agents run for 1 hour, that's 4 agent-hours. The key question: how many agent-hours does each plan sustain in a month?
Session-based tools (Claude Code, Codex)
Technically, there are 2 limits: the 5-hour session limit and the weekly limit. The Weekly Limit always is more constricting than the sum of all the 5-hour Weekly Limits.
For each experiment, I measured the Usage % at the start and end of the session, and get the difference. Since I know how many minutes the experiment ran, I calculate the "percentage consumed per minute" of BOTH the 5-hour session capacity and the weekly limit. Monthly projection: weekly capacity × ~4 weeks × 4 agents.
To normalize the "5 hour session capacity" to "weekly capacity", I figured that 7 days has 168 hours. Thus, 168h / 5h = 33.6 sessions. If I can reach 100% capacity in 70 minutes, then I can multiply that 33.6 sessions, and get 2,352 minutes.
Cursor's two-pool system
This is where the SOTA vs Composer insight emerges naturally from the math.
I measured the percentage consumed per minute of the monthly API pool (from the Opus-on-Cursor experiments) and separately the monthly Auto+Composer pool (from the Composer experiments). The API pool yielded roughly 1,065 agent-minutes per month, or about 18 agent-hours. The Auto+Composer pool yielded roughly 7,200 agent-minutes, or about 120 agent-hours. Combined: ~138 agent-hours.
The Max 5x → Max 20x projection
All of my Claude Code experiments ran on the Max 5x plan ($100/month). To estimate Max 20x ($200/month), I used Anthropic's published multiplier.
Anthropic's support documentation states that Max 5x provides 5x Pro usage and Max 20x provides 20x Pro usage — so Max 20x = 4x Max 5x capacity. This is a projection, not a measurement.
Off-peak and promo normalization
Anthropic's 2x off-peak discount applied to several experiments. I normalized by halving observed capacity during off-peak hours: conservative but approximate. I also ran experiments during peak, off-peak, and on the threshold of both.
When it was on the threshold of both, I just removed the values from the calculation. I was curious how the code would behave.
Codex's 24/7 2x promo (through April 2) was similarly halved. Both the promo and normalized figures are shown throughout for transparency.
Walking through Experiment 5
Let me show the math for Experiment 7 comparing Claude Code vs Cursor Ultra, both using the Opus 4.6.
Claude Code (Opus 4.6 1M window):
- The weekly limit went from 37% to 42% over 60 minutes with 4 agents — that's 5% of weekly capacity consumed.
- Weekly capacity = 100% / 5% × 60 min ≈ 1,200 minutes of 4-agent usage.
- That's with the 2x off-peak discount.
- Normalize to 1x: 1,200 minutes / 2 = 600 minutes.
- Monthly: 600 × 4 weeks ≈ 2,400 minutes.
- Convert to agent-hours: 2,400 / 60 × 4 concurrent agents ≈ 160 agent-hours on Max 5x.
- Apply the 4x multiplier for Max 20x: ~640 agent-hours.
Cursor Ultra (API Pool, Opus 4.6 200K window):
- API credits went from 0% to 26% over 60 minutes.
- Monthly API pool capacity: 100% / 26% * 60 minutes = ~231 minutes
- Normalize to agent-hours ~231 mins × 4 agents / 60 mins/hour ≈ 15.4 agent-hours.
- Since this experiment used only Opus (a frontier model), only the API pool was consumed. We borrow from above the estimated ~138 total agent-hours for Cursor's 2 pools for the estimates below.
In this single experiment, Claude Code Max 20x delivers roughly 41x more than Cursor's API pool (640 / 15.4), or roughly 4.6x more than Cursor's combined capacity (640/ 138). Other experiments produced different ratios depending on the model, discounting, and control tightness. The ~5x headline is the central estimate across all experiments.
This is back-of-the-spreadsheet math, not a precise benchmark. But for an order-of-magnitude comparison, it's enough.
Like what you're reading?
I'm writing more about vibe coding workflows, pricing, and techniques. Subscribe above to get notified when I publish, or connect with me on LinkedIn or on X.
Qualitative observations
A few things that don't show up in the numbers but matter for choosing a tool.
Composer 2 velocity was great. Some of the projects were were eye-opening: Composer 2 raced through an average of 7.1 projects to Opus 4.6's 2.3. This is backed by the velocity numbers (ask if you're interested the raw data), but experiencing it in real time was striking. Whether that speed holds up on complex, ambiguous tasks is an open question.
Opus 4.6 performed consistently across both platforms. Same model, same velocity on Claude Code and Cursor. The capacity difference between these tools is pricing architecture, not model quality. If you're choosing based on model capability, both platforms give you access to the same thing.
Token consumption is volatile day to day. Model updates, features, regressions, and discounting all hit during the same period. This may have caused noise in the experimental data, but it's also representative of daily life at a particularly active time in the technology and business of AI coding tools.
Key takeaways
1. The capacity gap is real: ~5x combined, ~38x on frontier models. If you use Claude Code with Opus (its default), you get substantially more runway per dollar than Cursor. If you only compare frontier model access, it's not close.
2. To make the most out of Cursor, you should be using Composer a lot. Most of your Ultra budget buys Composer credits, not SOTA access. If Composer fits your workflow, you get ~138 agent-hours and strong velocity. If you want frontier models full-time, Cursor becomes extremely expensive per agent-hour. A common pattern is to use SOTA models for initial planning and research, then Composer models to implement the plan much more rapidly.
3. Velocity matters — Composer 2 is much faster at completing projects. More capacity doesn't automatically mean more output. An engineer running Composer 2 on tasks may complete more work in 138 hours than another running Opus.
4. The pricing model shapes your workflow. Claude Code's speed-limit model rewards consistent daily usage with parallel agents. Cursor's monthly budget is more forgiving for bursty schedules. The "best" plan depends on how you work, not just the capacity math. (I covered this difference in Part 1.)
5. Codex is a real contender at ~1.6x Cursor's capacity, and a number of engineers I know and follow online have been enjoying Codex for its knack at solving harder problems that Opus 4.6 may have challenges with. And you get the SOTA model for all the agent-hours.
6. With Anthropic's "capacity reductions" for 7% of users, I ran out more often in the 5-hour session, but not necessarily the weekly session. I'm not 100% sure yet, because the measurements keep fluctuating. But the weekly session seems to be similar to what it was before. And since it is the constraining factor, running out of 5-hour sessions may not necessarily mean that I have overall fewer tokens per month.
Caveats and open questions
This section is long on purpose. The caveats are as important as the findings.
Experimental design limitations
No two experiments were identical. Models changed, plans changed, promotions came and went. Each experiment is a snapshot of a specific configuration on a specific day.
I was the human bottleneck. Confirming "done" claims, assigning projects, occasional breaks; all of this introduces noise. Semi-autonomous mode created asymmetry across tools: each tool pauses at different moments for permission, which affects velocity differently and is unavoidable.
Also, velocity was not the primary objective, since I was interested in token capacity (or agent-hours). In particular, code quality was probably decent but not audited. From my experience, the AI agents usually get most of the way to the finish line.
And, Codex and Claude Code both have lighter, faster models (e.g. GPT 5.4 mini, Sonnet) for varying speed and token usage.
There are many interesting variables and questions, and I didn't test them out for the sake of time.
Limitations in measurement and extrapolation
The whole purpose of this experiment is to normalize across tools that report usage in fundamentally different units, and that's also the main source of imprecision. Claude Code reports percentages of session and week. Cursor reports dollars for API plus a separate pool for Composer, with a combined total. Converting between these systems requires assumptions.
Resolution of the measurements is often low low. If your measurement jumps from 0% to 3% in an hour, the true value could be anywhere from 3.0% to 3.99% — a roughly 33% range of uncertainty. For that reason, I ran multiple experiments to get a sense of averages and ranges. Using 4 agents helped me accelerate burn to see more numerical change in less time.
I simplified my extrapolation for agent-hours by multiplying the weekly estimated agent-hours by 4, totaling 28 days. Technically, the average number of days is slightly over 30.
The chaotic experimental window
I get the sense that something around March 13 or March 14 may have changed Claude Code's token burn to accelerate.
Moreover, the 2x off-peak discount launched March 14 and ended March 28. I normalized by halving, but the normalization is an approximation. Composer 2 shipped March 19, Experiment 7 may not represent steady state, though Experiment 8 (March 20, no discount) confirms the pattern. Codex's 2x promo was active through April 2, normal-rate Codex may be go to 0.8x rather than ~1.6x Cursor. Or, focusing on frontier models, 6.2x instead of 12.4x.
I could have waited for a quiet week. But there hasn't been a quiet week in AI coding tools in months. This chaos is normal usage — the launches, the promotions, the regressions. A perfectly controlled experiment would be more precise but less representative of what you'd actually experience.
Open questions
- Does the capacity gap change for different work types: greenfield vs refactoring vs debugging?
- What about for tech stack? I was doing full-stack engineering in Elixir/React/Terraform. How does that change for Python/Svelte/Pulumi? Firmware? Mobile? SRE? Database internals?
- What's the quality gap? If any of the models speed comes at a quality cost, the velocity advantage shrinks.
- How does this look on team and enterprise plans, particularly Claude Code Premium Seats in Teams?
- Will these numbers hold as all the companies adjust pricing and models adjust velocity?
Tips for reducing token usage (to get more work done)
I wanted to share a few resources I found online or heard while discussing this with friends and colleagues for reducing token usage.
If you're using Opus, consider switching to Sonnet as your default model. A few of my friends report that Sonnet is similarly effective, but faster and more token efficient. I've been mostly focused on Opus, so I can't speak to this directly.
Reading Claude Code best practices. Regardless which tool you're using, some of the concepts in the guide may help you out.
Clearing context more frequently is an easy change. My experiments ran on models with 1M context, and I just let them run and auto-compact over the course of the hour. I believe the whole conversation gets sent up (minus caching effects), so this clearing might be impactful.
Cron job 2-3 hours before you start your work day to send Claude/Codex a trivial message. Given that the 5-hour session limit is a constraining factor, consider that you typically have 2 sessions in an 8 hour work day. You can get a 3rd window if you trigger it before you start the bulk of your work, so you can tap into a 3rd window in the day. Note that in the end, you'll still hit the weekly constraints.
Use "token-reducing" libraries like RTK. The premise is that a lot of CLI binaries that the AI coding agents call generate noisy output that is bad for LLM's. It creates a proxy to optimize the tokens. Consider looking for more, since this is a class of tooling. In the CLI, there is tokf. There are also prompt compressors like Microsoft's LLMLingua.
Current events: recent news about recent token costs
At the cost of extending this article further, I wanted to highlight a few recent items of news as it pertains to this analysis.
On March 5, 2026, Forbes reported that Cursor's internal analysis showed that the $200/mo Claude Code subscription could get $2,000 of tokens at the end of last year, and in early March 2026 was getting $5,000 of tokens. On the other hand, compare that to Cursor's $200/mo plan offered $400/mo of API usage + "generous Auto+ composer", which we've shown to be considerable. But the reason I was interested in this experiment is to begin to translate it to "how many hours of engineering work can I do with this?" and begin to quantify this.
Also on March 5, 2026, investor-entrepreneur Chamath Palihapitiya tweeted that his company 8090 chose to migrate off of cursor because AI costs have tripled since November 2025, and are "now spending many millions per year", and "trending to $10m per year". He mentions that it may be how the engineers are using the tooling as well, e.g. running runaway loops ("Ralph loops") without regard to cost. But the main point is that it's a topic of interest and an area worth thinking about.
Around the weeks of March 14 - March 26, users were reporting increased token burn rates. (See my LinkedIn posts noting my initial observation on March 14, then my LinkedIn post when it trended on X on March 25). It looks like Anthropic announced a capacity change on March 26, and estimated it would affect a minor ~7% of users. But as of publishing this article (Mar 30), it seems like they're still working on it. I don't know what's been happening internal to Anthropic, and I'm interested in following along.
I speculate is that Anthropic tweaked the 5-hour token limits which helps them with scale, but the weekly token limits didn't change that much. If that's true that the weekly token limits don't change much, then overall monthly token capacity doesn't change much. It just means you run into the limits a lot more per day. (You might try that cron job I mention above.)
Anyways, this article represents a moment in time as our use of the tool and the pricing models around it change. Last June/July (2025), Cursor changed its pricing models in a way that upset users. I wouldn't be surprised if this continues to change, and other engineers/entrepreneurs have said the same.
Wrapping up
Phew, that was a lot. Thanks for sticking around to the end.
This started with a pricing question and ended up capturing a LOT more. While the technology, pricing and business will continue to evolve, I wanted to do this deep dive to understand a snapshot of the ecosystem today. As things evolve further, I can have an anchoring mental model to reason about future changes.
The choice isn't just "cheaper vs more expensive." It's what kind of capacity you need. Frontier model capacity for complex reasoning? Reach for Claude Code or Codex. Fast implementation throughput on well-scoped tasks, or you prefer an IDE? Cursor Composer has a real speed advantage when you combine frontier models for planning and troubleshooting with fast, lightweight models. Most engineers probably need some of both — the question is which default fits your workflow.
I plan to keep running experiments as both tools evolve. If you're interested in discussing the findings, in seeing the raw data, or in talking about token math, I'd like to hear about it: connect on LinkedIn or subscribe above.
This is Part 3 of my series on transitioning from Cursor to Claude Code. Catch up: Part 1: Stuck at 16%, Part 2: Parallel Agents.