Measuring AI coding adoption: What I learned as a manager
Increasing AI adoption is common objective for engineering managers. Beyond qualitative surveys, what else can we do?

Let's say you're an engineering manager, and you're participating in an organization-wide campaign to increase the adoption of AI. The initial goal is to get people to use the AI tools.
That's easy: hand out licenses to your team for Cursor, Claude, or GPT. Congratulations! What's next?
Maybe you're among the early adopters in your company, or maybe the initiative originated elsewhere. Senior leaders across companies are investing in AI because they see the potential of greater velocity and more expansive creativity. But they're also responding to pressure from their stakeholders: board members asking for slides about AI strategy (both internal and customer adoption), investors who expect adoption to keep up with current startup pace, competitors making the same bets. They need to show these investments are paying off.
Meanwhile, these AI tools cost real money. I've spoken to startups who are spending $1,500 / month / engineer as they seek to understand the new paradigms of coding and insights for building leaner. This is a major step above startups who were previously spending $300 - $500 / month / engineer. Even for enterprises who spend $5,000 / month / engineer, adding $1,500 / month would be a big leap in investment.
In March 2026, Jensen Huang (CEO of Nvidia) said that senior Nvidia engineers earning > $500k in salary should be consuming well over $250k of tokens per year. This sort of paradigm shift hasn't rolled out broadly in the industry. But talking to folks on different teams and seeing my own usage, I don't think it would be difficult for engineers to spend $1k / month ($12k / year).
For that kind of cost, it's important to know what value your team is getting and to optimize the organization's usage to make the most out of that money. But what's the outcome? Should engineers max out tokens? Or max out lines of code? It's a new paradigm, and you're trying to make sense of it.
In Part 1 of this series, I wrote about the rough edges of vibe coding from the engineer's perspective: things in production that slow down engineers when you move AI coding from side projects to production.
This article tells the story from the managers' perspective, based on conversations with engineering managers and my own experience. What does it actually take to drive real AI adoption on an engineering team?
How do you actually measure adoption of AI coding?
Managers I've spoken to say that they're being measured by senior leadership based on the number of licenses they've distributed (or not distributed) to their team. They're counting PRs and lines of code, and doing qualitative surveys of team members to gauge AI adoption. But these don't tell you whether adoption is meaningful to the business and customer.
Research suggests that bulk license distribution won't lead to actual usage. Gartner found that often fewer than a third of purchased licenses see active use after several months. The 2025 Stack Overflow Developer Survey tells a similar story: 81% of professional developers surveyed are using (or are planning to use) AI, but 41.4% of professional developers believed that AI struggled with complex tasks. (Note: that 41.4% level dropped since the previous year, but is still high.)
Even with usage, I've found that volume of AI tool utilization and the variety of techniques in regular use is uneven across organizations and even within a single team. So even with licenses distributed, uneven training is a distinct challenge.
So how can we assess adoption?

As a practical experiment, try speaking with a sample of the team in your 1:1s about how they use AI, and perhaps collaborate with them on a project. It's more effective to see how your team uses AI (e.g., during a demo, presentation, or pair coding) than to verbally poll them. That way you can see how they're using AI, rather than a simple yes/no poll.
Are there more concrete metrics of adoption?
I also find it helpful to use a quick but highly flawed (and highly contentious) metric: token spend. This is the theoretical cost of the tokens a person uses. It's often subsidized under a monthly license, or an enterprise agreement.
For token cost, here's a rough rule of thumb for token spend: state-of-the-art models like Claude Opus or GPT-5 can easily cost $100/day of heavy use (of tracked token costs, not necessarily real dollar spent). For folks that aren't past the $20/month base subscription tier, they're likely not yet "vibe coding". That's not bad, it's simply a metric to ballpark usage volume.
Maximizing token usage is not an end in and of itself. Token spend is a cheap, weak signal, and can be gamed. But it's available right now without additional tooling. (Note: it's also wasteful to optimize for high-cost workloads). But I've found it helpful to ballpark my own style of adoption from token costs. When I'm in a totally different ballpark from someone else, it's a helpful signal to trigger me to ask why.
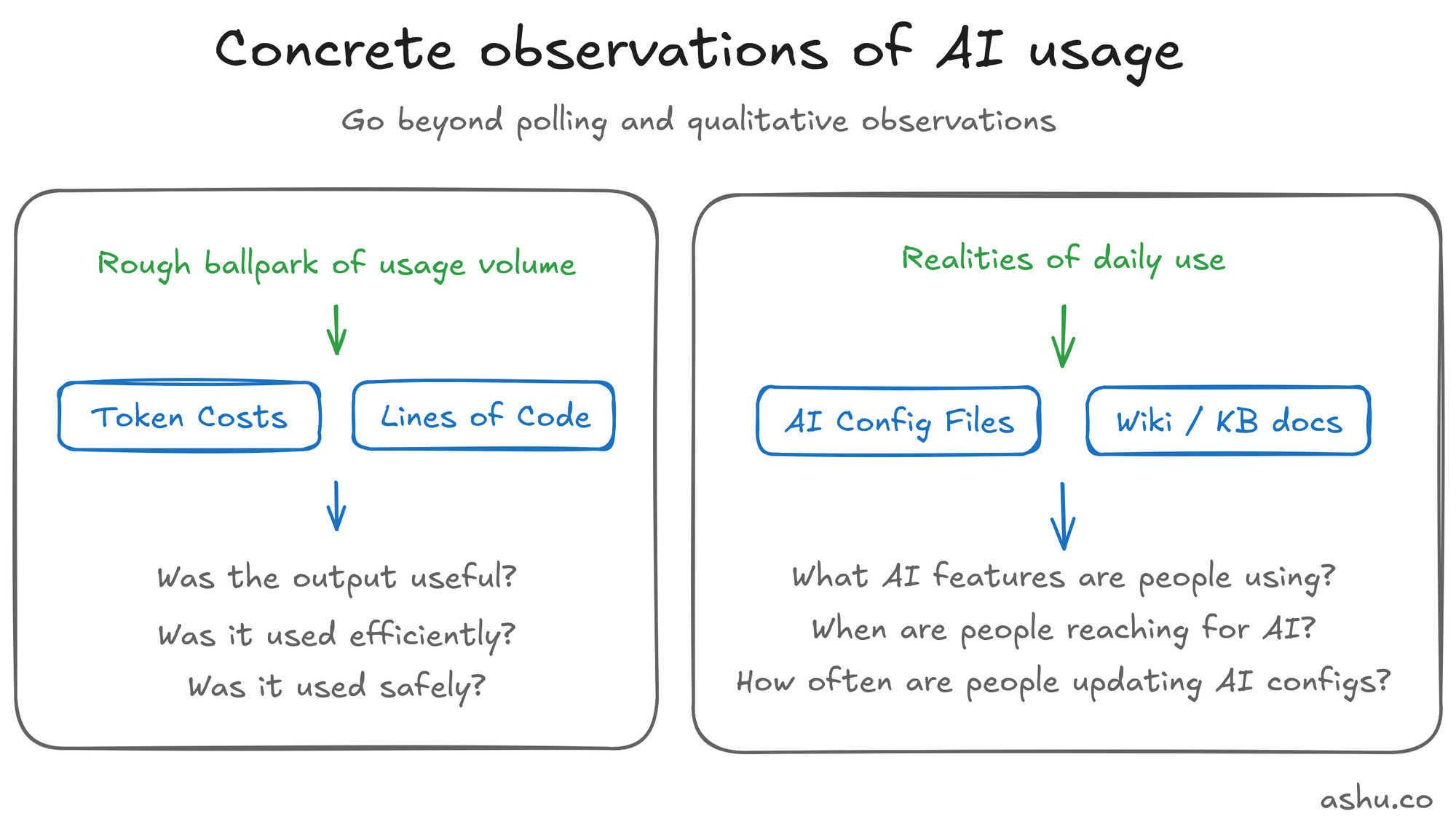
Here are a few other metrics worth considering, other than token costs:
Lines of Code. This is another deeply flawed metric (and famously so), but it's a useful factor to consider because there are real implications for code reviews as well. When PRs are changing from hundreds of lines to thousands or tens of thousands, this hints at changing AI adoption styles. But you should also think about the quality of code reviews.
Maturity of AI configs, context and tooling (e.g. agents.md). These are typically markdown files shared between engineers in the repository. Or maybe it exists as instructions / documentation in your team's wiki / knowledge base (to find relevant docs, search for "Claude" / "Cursor" / "Codex").
Maturity of AI configs is perhaps the most interesting sign of usage, because it shows AI being used and customized. Is your team using Skills, Subagents, Agent Teams, Automation like Routines? How often are these configurations being customized? These configurations fall out of date, so teams regularly using AI are likely to be measuring and tuning their AI configurations and documentation.
Understand your team's perspectives on AI adoption before acting
To return to the topic of polling and observing your team in action: your team may have legitimate concerns blocking adoption. There are legitimate concerns about security and code quality, and the benefits aren't evenly distributed across experience levels (more on both below).
Some senior or SRE engineers have told me that their work involves precision, complexity, or high risk, and AI is an unacceptable risk. Or maybe the team is too busy to try out that new tool, and they need someone to be brave and test it out first in your environment.
Before pushing to increase adoption or spend, talk to the team.
This is the step that is easiest to skip over. It's tempting to see low utilization and lean into the instinct to push harder: more training, more encouragement, more tooling. But the question is about workflow, mindset, and preferences, and the answer will differ per team.
Sidebar: It's also valuable for you to try out different AI workflows. Some of the managers I've spoken to are themselves skeptical about AI. It's valuable to suspend your disbelief for a few days and experiment. Have some fun with it; play a bit like you got some shiny new gear and you can build whatever silly thing you've been meaning to for a while. Greenfield projects, CLI scripts, or small bugs are great starting points. Try out a markdown plan, and play around with easy parallelism.
How you engage with your team depends on where you sit. As a line manager, you're close enough for 1:1s and small team discussions. Ask to pair code directly. Ask people what's working and not working in their CLAUDE.md or .cursor/rules/*. Ask what they reverted last week due to AI. The goal is to identify specific concerns, pushback, and knowledge gaps: not to audit or blame.
If you're a senior manager, you may need to shift organizational momentum more broadly: clear communication about organizational objectives, setting metrics to measure progress, funding training (both money and time), or setting explicit norms that AI tool usage is supported and expected, and reflecting on which metrics helped and didn't. This is a different communication problem than a 1:1.
Listen for objections and disagreements: they're valuable signals. Engineers who say "AI is inconsistent" aren't wrong. I've measured token consumption that varied by 2x session to session for identical work. Harnesses regress. (By harness, I mean the Claude Code harness that wraps the Claude models.) Prompts that worked last week hallucinate this week. Take these concerns seriously.
The part nobody budgets for: coaching for AI coding
After I recognized these signals, I started testing them out on my teams, among friends, and with strangers I met. I realized that the gap often wasn't tools or licenses: it was listening, persuasion and coaching.
I spoke with a number of skeptics, but there were also a lot of folks who wanted to vibe code more. Quite often, they didn't have the time to keep up with the firehose of new information. And another frequent concern was that they were worried about vibe coding in production environments, or in local environments with permission systems (e.g. credentials for AWS, SSH keys to machines set up for thoughtful humans). Specifically, I'm referring to the adoption of "hands-free" vibe coding and not AI coding where engineers are manipulating code or commands.
Moreover, adoption wasn't uniform. Some engineers had been happily vibe coding, and I spoke to them to see what worked. There was a spectrum of skeptics and aficionados, and the information needed help to spread faster. Research published in Science (Daniotti et al., 2026) found that AI productivity gains (more commits, broader library use, exploration of new functionality) accrued mostly to experienced developers, with early-career engineers showing no statistically significant benefit.
Other studies, like Cui et al. (2026), found the opposite in controlled corporate settings: less experienced developers benefited more. The takeaway for managers isn't that one study is right and the other wrong: it's that the gains aren't uniform, and that deserves special consideration when you're planning training, setting expectations, and measuring progress.
At the time, I was specifically interested in how to do DevOps / operational / maintenance work safely. So I thought through what kinds of tedious tasks people would like to do less of, filtered out risky operations, and then built starter configuration files, subagents, and shell scripts. (I'll elaborate in my next post.)
After posting about it, and sharing it in team meetings, I realized it required more active persuasion (as opposed to passive announcement). So, as one does, I switched from optional knowledge-sharing sessions to more proactive 1:1s, and team calls.
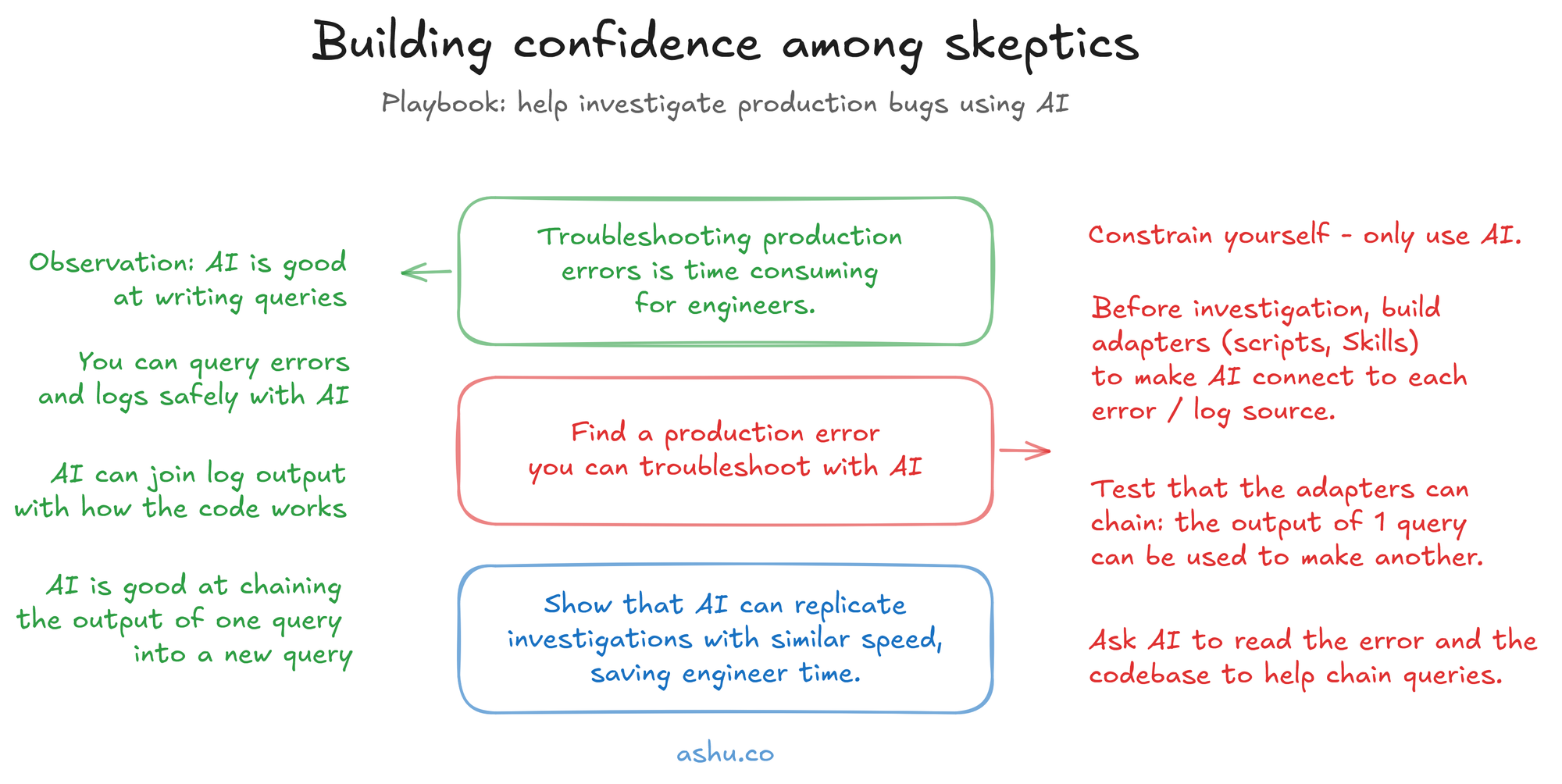
I also tried another playbook: to build confidence among skeptics, I also troubleshot production issues in parallel with other engineers troubleshooting those same issues. I constrained myself to use mostly-autonomous AI agents (equipped with a context system). I accumulated 2-3 concrete examples where AI can help engineers step into unfamiliar parts of the codebase to troubleshoot an on-call situation. This helped spark ideas for methods and techniques, and overcame some mental blocks.
Two key things that helped out when conducting knowledge sharing sessions in my most recent campaign: hinting at how it could be used more safely in production, and teasing out specific concerns that engineers had but hadn't voiced yet.
When you see lightbulbs go off, it's incredibly rewarding. But the work to get there is often invisible in your current metrics. And it requires changes beyond conversation: to the codebase, the tooling environment, and how your team works day-to-day. As mentioned above, I'll cover the concrete technical stuff: agent configuration files, sandboxed execution, CI pipelines, and workflow changes in my next post.
What I'd do this week to improve adoption
To distill my ideas and anecdotes above, here are 3 things I'd suggest that could be done as small projects and experiments you could do in a week:
Hunt for adoption through quantitative and qualitative signals. Look at the numbers you already have: token spend per engineer, AI-assisted PR rates if your platform tracks them, git commit footers that show AI assistance. Then pair those with qualitative input from team retros, 1:1s, or a short survey. Neither signal type is sufficient alone. Token spend sheds light on how deeply your team is using the tools. Conversations tell you how and why (or why not). The combination replaces guesswork with a baseline you can act on.
Tease out the obstacles getting in the way. You're not going to get far with "are you using AI?" Instead, surface specifics through whatever channel fits your team: 1:1s, retrospectives, Slack threads, brown bag sessions, pair coding sessions. What tasks are they using AI for? Where did it break down? What would make it more useful? The goal is to map the gap between where your team is and where productive AI usage actually lives, then address the top blockers, whether those are configuration, training, trust, or tooling.
Pick one process to automate. Show concrete examples of its benefits. Don't try to overhaul everything. And remember, it's not just code generation. I gave the example of troubleshooting production errors. It could also be: a planning template, a test generation step, a deployment checklist, an observability alert summary, or updating JIRA tickets. Isolated wins build confidence, both yours and the team's. They also give you concrete stories to share with leadership when they ask for evidence that the investment is working, and can be cross-pollinated across the wider organization.
The gains from AI are real, but there will be new problems
When coaching resonates and the adoption picks up, the individuals on your team will be equipped with new career skills and your team will ship faster. Engineers tackle problems they would have avoided before.
But adoption was only the first thing you needed to measure. Once your team is using AI coding tools for real, a new set of problems surfaces: bottlenecks that shift in unexpected directions, quality concerns that span multiple dimensions, and a measurement layer that hasn't caught up yet. I'll dive into some of the technical areas there in Part 3.
In the meantime, I'm collecting stories from engineering managers working through AI adoption. If you're in the middle of it, I'd like to hear from you. What metrics are you using? What pushback surprised you? Reach out on LinkedIn — these conversations are the most valuable part of this work. I'm happy to swap tips and ideas!